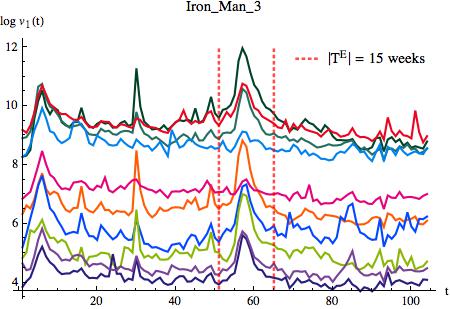
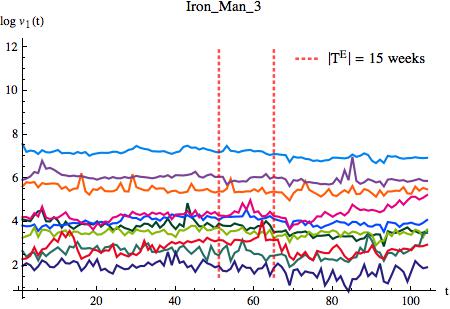
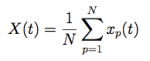I built a WikiNet (a Wikipedia subset) starting from the article of a recently released movie, and I considered visits history of all articles in the WikiNet, one year before and after the movie release. We will see how the exogenous event, related to the movie release, influence the number of visits of the articles in the network.
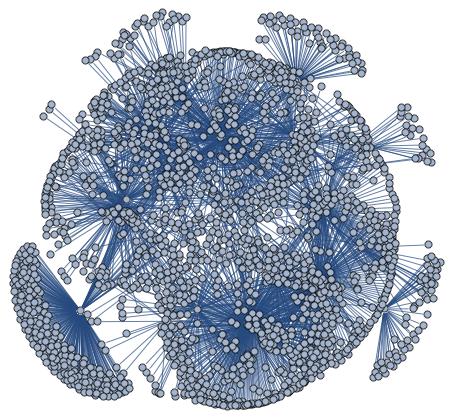
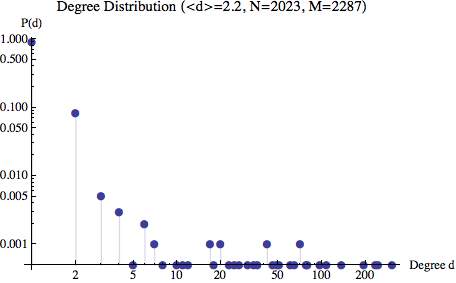
I chose a well known movie, Iron Man 3 (released on May 3rd 2013 in USA), in order to have a lot of visitors and a lot of links in the network. I extracted the local neighborhood in Wikipedia as I described in a previous post and I obtained a non oriented graph. Of this graph I considered the central page, all its 461 first neighbors (FN) and just a random selection of 1 000 effectively second neighbors (SN), because some SN could be already FN. I had to restrict my analysis to a subset of articles for computational limitations. Downloading and processing time series for 24 months and for around 4 000 articles was far beyond my possibilities of time and computing power. Nevertheless my analysis is performed on a significant data set.
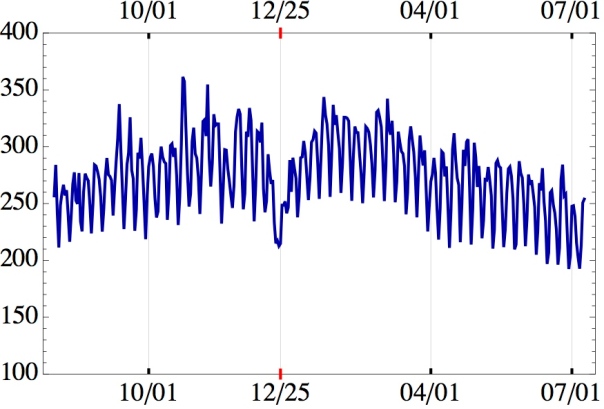
I considered a the time window of 24 months, and for each article I considered the weekly average and its logarithmic value. First of all I had to remove the effect of the weekly pattern of Wikipedia articles, described in this post, a global and regular fluctuation. Second, I had to reduce the differences among articles, because their typical average number of visits can be very different, and considering the logarithmic value is a valid choice in cases like this.